

The past few months (read: since February or March of 2018) has not been kind to the ADM 8 project. Every single instance I’ve put time aside to work on it, other things have been more important. However, in the past few weeks, I’ve been able to put some time aside for some major upgrades to the project albeit ones that are not yet entirely visible. A major reason that did so little work on ADM8 over the past year is that frankly, transcribing documents was a major pain. (A second major reason was two months with the Coast Guard last year, and then working a new full-time job from February 2019 that left little time/energy for other things). In this blog, I described the process that we had before. In this blog, I further described the process for uploading the reports to the database once they were transcribed. The process of first transcribing the documents into .csv files, and then using scripts was creating several instances for errors. Errors could be introduced by the presence of things like spaces and other extraneous text, typos, or the selection of the wrong existing record in the database when presented with a choice of individuals or ships of the same name. I am certain, for instance, that there are currently issues with the Pett family and how ships are attributed to shipbuilders.
This multi-step process was incredibly frustrating as I had to load individual reports several times in order to correct mistakes. Further, when the records were being transferred from the database on my laptop to the database at the host’s server, there were issues because the servers weren’t necessarily configured the same way. I decided- finally- to create as part of the website a document transcription interface. In this blog I will discuss the design of the transcription interface, and how the transcription process compares to the previous model.
In many ways, managing transcription is about managing where the effort and the work go. When transcribing to a CSV file, it’s relatively easy at the beginning, because one is just writing to a spreadsheet effectively. Much of the effort comes later, when dealing with the entire report as a whole. Because of the way I set up things, if there were errors with a report, it easier to wipe all the records from the database, fix the errors in the file, and then run the scripts again. However, this was extremely frustrating.
With my new transcription model, much of the effort is at the front end. First, of course, in the creation of the transcription interface itself. However, by working with the website, and with the actual database, there’s a lot of problems solved. For example, I don’t have to worry about the differences in how the database is set up on my laptop and on the website’s servers (which I can’t control). These differences- for example with the character sets, can be problematic.
So let’s have a look at the interface.
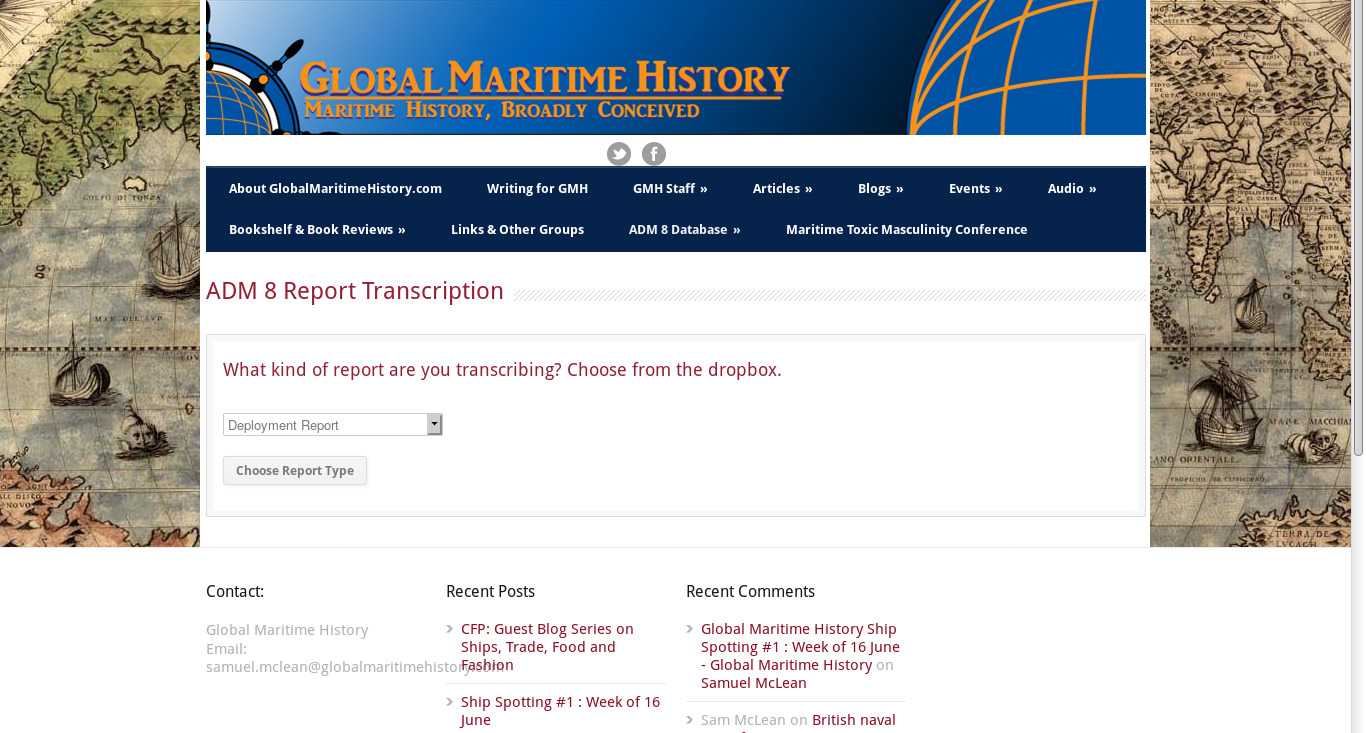 So the first page of the Transcription Interface is choosing the task- the way I’ve coded it, everything’s in a single file, with choices depending on what kind of report is to be transcribed. Since Deployment Reports are the vast majority of the first two volumes of ADM8, they’re the only ones that can be transcribed through this interface at the moment. There is also the option of *continuing* to transcribe a partially completed report.
So the first page of the Transcription Interface is choosing the task- the way I’ve coded it, everything’s in a single file, with choices depending on what kind of report is to be transcribed. Since Deployment Reports are the vast majority of the first two volumes of ADM8, they’re the only ones that can be transcribed through this interface at the moment. There is also the option of *continuing* to transcribe a partially completed report.
The second page, if starting a new report, looks like this.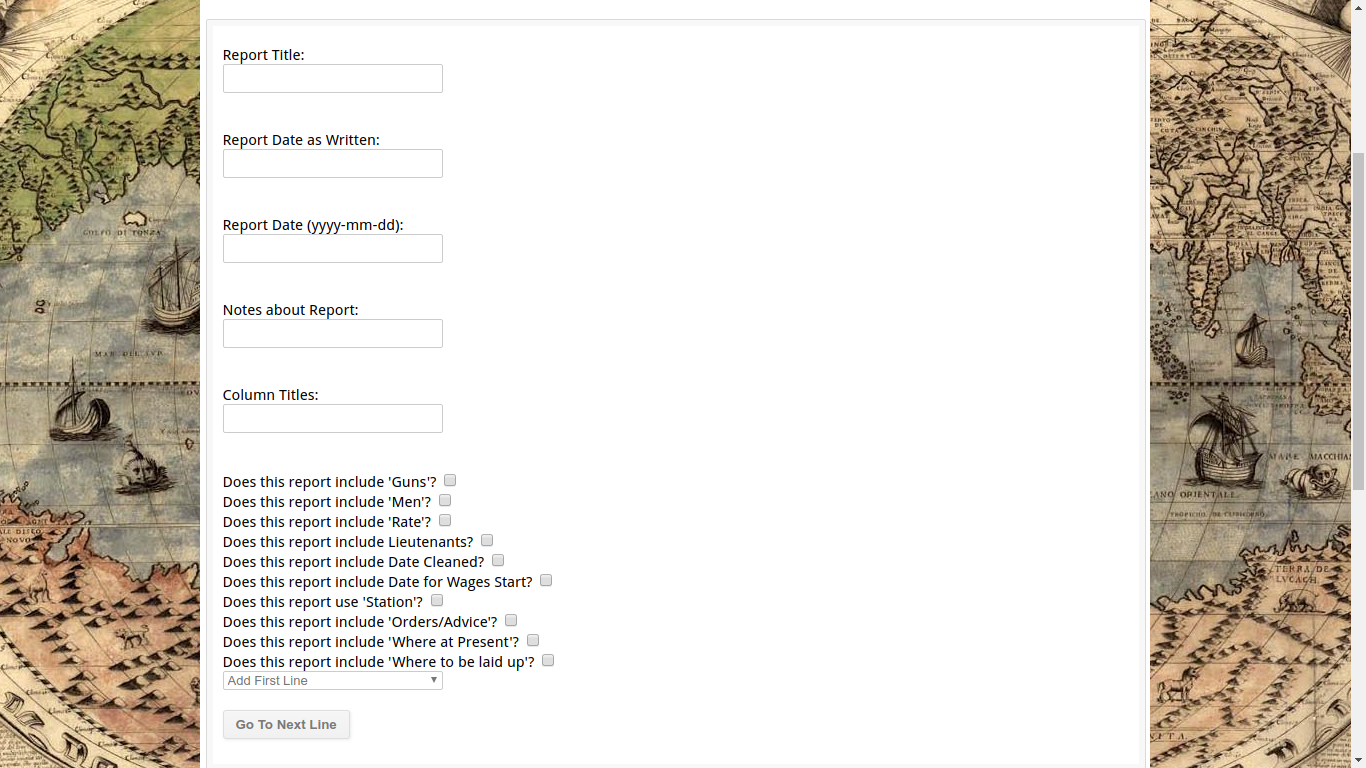
So previously, with the CSV file- there were columns for all the different fields- and if they weren’t used for the report, ‘N/A’ was entered. This created problems for displaying reports (because I didn’t want the visuals cluttered with lots of N/A) and because I thought creating flags would be an issue. So I had this stupid workaround where if line 0 of a report had ‘N/A’ for a field, it was skipped. This was problematic if the report began with a subtitle (and so I’d have to give that line a number of -1). As you can see, what I’ve done here is accept that using flags is a much better way of doing things. By flag I mean that in the ‘Reports’ table of the database, each line has a series of 1 or 0 values for various things. What you see above are the flags for the ‘Deployment Reports’. Inevitably, each type of report will have its own flags- and so there will be lots and lots. And I felt awful about that, which is why I didn’t use flags to begin with- but I’ve realized, it’s a database, it’s smart. It can deal with defaulting flags to 0 values when creating lines. I will admit one of the biggest issues I’ve had with working on this project- and improving the project- is how long it took me to be willing to use even the middling abilities of SQL and the various tools because I worried it would be too much of a burden. I realize now it’s much easier to check a bunch of flags in one table then have to go to another table and check values there.

Once the basic information for the Report as a whole has been entered, the next step is to start transcribing lines. Here, there is a shift in effort, because lines have to be transcribed one at a time. This seems like a pain, but in practice it’s much faster. What you see here is what is shown when continuing to transcribe a previously started report. Also, this table is at the top of the page every time, so that the transcriber can see that the previous line was entered/saved correctly. My next step is to add code so that the ‘secondary’ rows are also shown (for the last line entered). These record every time an officer or location is mentioned (for a deployment report) so that researchers can later pull up all the mentions of a single individual or location.
As you can see, this form accomodates both Subtitles/abstracts/etc lines, and regular lines- if it’s a subtitle, simply tick the box, put the text in the text box, then head down to the bottom and on to the next line.
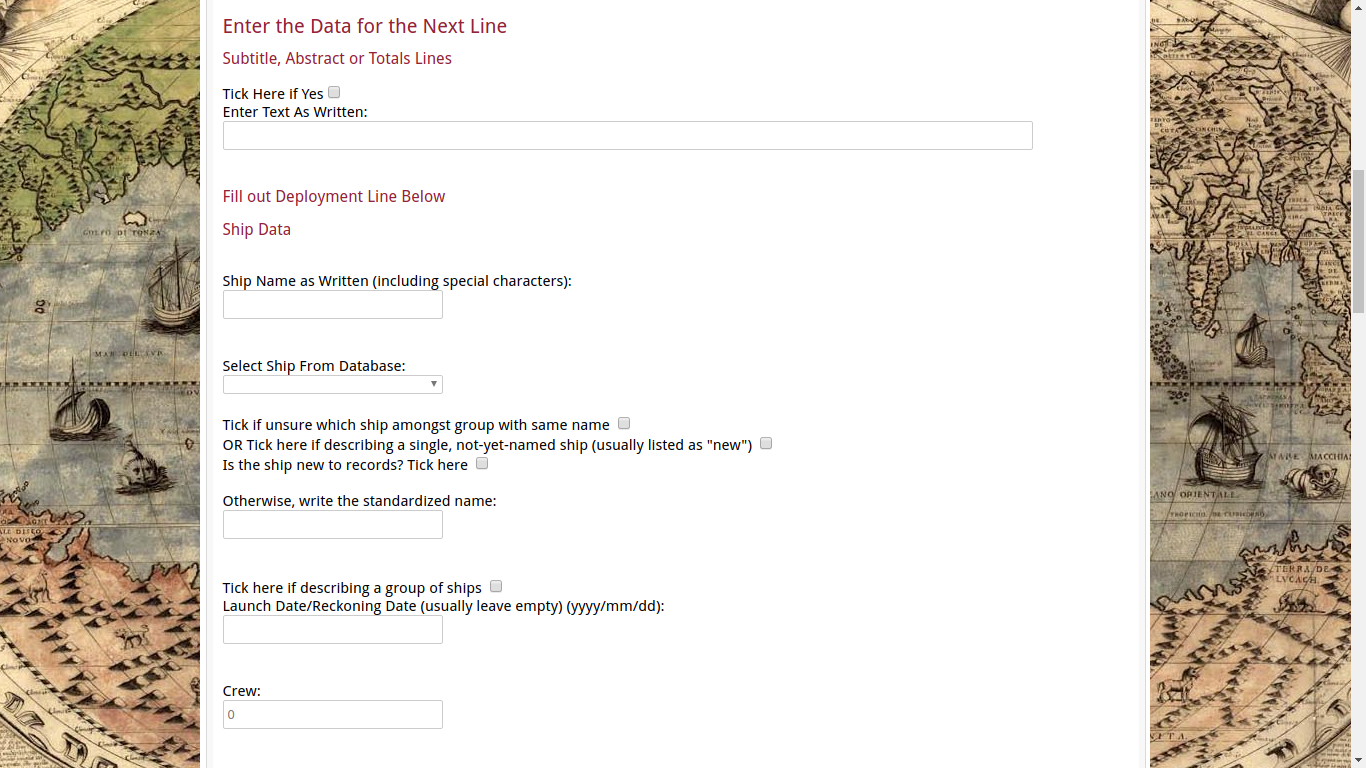
However if it’s a regular line of data, things are a bit more complicated.
So one of the issues we had with the CSV file was issues with associating the record with the correct ship already in the records- it was presented to me as a list of which I had to choose one- sometimes, I’d hit the wrong number and hit enter while rushing. Therefore, errors. What I’ve done here is used a dropdown list (where you can actually hit the first few letters to bring up the ship). This does help reduce errors. Further, it provides a space for how the ship’s name is actually written in the report. On top of that- it’s hard to decide sometimes which ship is which- for example there are a number of tenders named Anne & Christopher. If the transcriber can’t figure out which- there’s a tick box for that. And if the ship is new ship being built but not yet named, or if it’s a group of ships (for example, ’12 yachts’ or ‘4 Horse Barges’ or something like that. If the ship is new, there’s a way to enter that too.
As you can see, there’s a default value of 0 for the crew- things break and the record can’t be entered if that’s a blank value, so it was easier for me to put in a default value, which is what is entered if the field is blank.
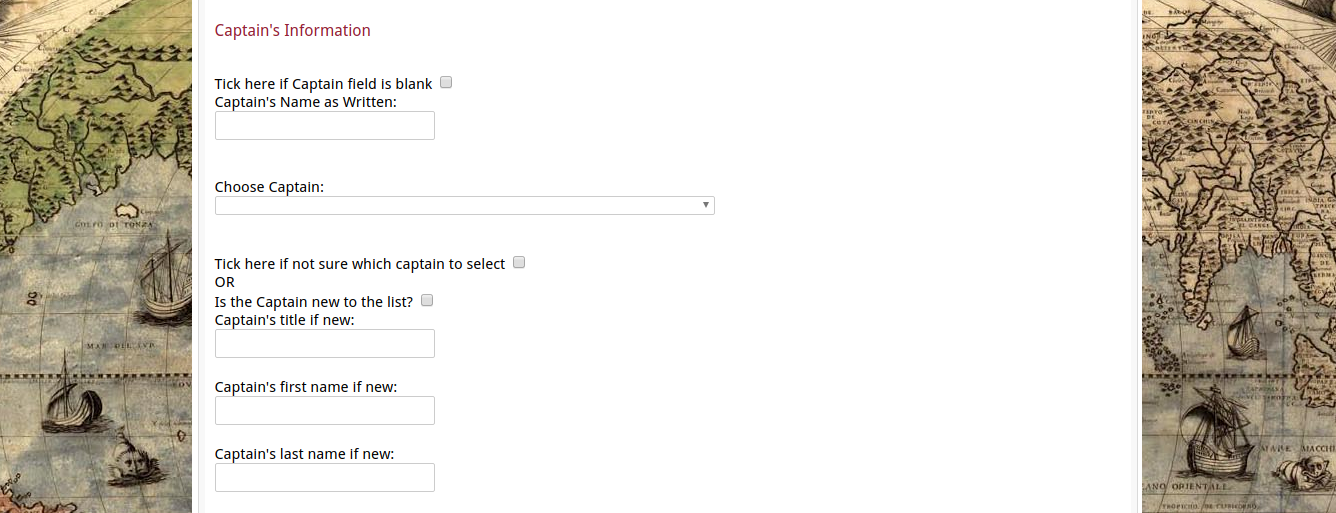

Here we have the sections for the Captain, and the Lieutenants. Similar to the field for the ship data, mostly this is chosen from the dropdown lists- which actually pull their data from both the live officer lists, and the ‘temp officer lists’ from the previously transcribed (but not made live) reports. The dropbox is bigger for the lieutenants since it’s possible to select more than one officer from that list. Here, instead of default values for blank fields, I use tickboxes. Again like with the ships, there is a space for adding new records to the database as well, and for indicating issues with differentiating between officers of the same name. (Like the damned Petts).
At the bottom- not used for this report where I grabbed the example imagery from, but a few reports include ‘Date Cleaned’, ‘Date Wages Start’ and things like that.

Here we have the final few sections. Location data- like with the ship and individuals, there is a difference between recording the information as depicted in the report (which is put into the Station and Duties as Written and Where at Present Fields (as well as the where to decommission etc field when used), and for recording which locations mentioned. This was problematic in the CSV file, because I wanted to have the transcription resemble the report as much as possible so I used as few extra columns as possible. Here, I’m not worrying about it- I’m just making it possible to capture the information as accurately as possible. Like with the Lieutenants, multiple options can be selected for locations as well.
For the Archival Reference field- this is important because the research tool is designed to bring together individual lines of many different reports, so this is important to capture which page of the documents it can be seen in the actual archival volumes. Usually, this has a default value as well.
Finally, the transcriber has the options of moving on to the next line or viewing the entire report to confirm that it can be sent to the live database. The latter function is not working yet- and my next goal is to write the code so that the transcribed reports can be moved over, individually.
My experience so far is that the accuracy rate is much higher, and that it’s actually as fast if not faster than transcribing to the CSV file, and without the kerfuffle of having to run through multiple PHP scripts to put into the database. Overall, it is a faster process (setting aside the delays of my ability to put time aside to do the coding for each step).
I hope to – in a few weeks time, have a blog about the interface for checking and correcting reports before making them live.




Pingback: Global Maritime History Request for Volunteers - ADM8 Project Document Transcription - Global Maritime History