

In the previous entry in the series, I examined ADM 8 volumes 1 and 2, the documents for the initial phase of this project.
In this entry, I’m going to talk about the database design at length. To be honest, I had quite a bit of trouble with the database the first time, and the first design I used didn’t work particularly well. In particular, I didn’t understand how important it is to really micromanage every aspect of the database, from structure to attributes to naming. Or at least, work in a consistent manner This blog will delve too far however. For one thing, at the point of writing (November 2017), several types of reports have not been transcribed/incorporated into the project yet (Although this will change in the next few months). More to the point however, another page will be created to be a reference document created so that researchers can create their own queries.
Technical Details
This website is built using a content management system called ‘WordPress’, which is built upon a number of technologies. The ones that matter- so far- are HTML, CSS, the scripting language PHP, and a MySQL (or mariaDB) database server. The importance of the first three will be discussed in the fourth blog of this series, in which I talk about the development of the front-end/user interface. Since WordPress is built upon MySQL, that meant I needed to use MySQL for this project. This isn’t actually a problem, beacuse MySQL is pretty good for databases which involve a lot of *read* operations- which is what this project will be once all the reports and documents are uploaded.
Although WordPress is based on MySQL, there are no plugins that replicate phpMyAdmin (a program which allows administrators to use a browser to manage databases), specifically in providing functionality to create custom tables a custom structure, or to upload a number of already-filled tables into the existing WordPress Database. However, because I have recently taken more direct control of this website, I now have access to these administrative functions. I use phpMyAdmin to directly add my custom tables to the database.
Database Structure and the Documents
I actually struggled quite a bit with designing the database. Once I realized that it’s about associations, and that repeating pieces of information with the database isn’t a bad thing, then I was able to move forward quite quickly. I have ended up with some duplication of information across the database, but this makes extracting data for different purposes much easier.
Tables
In this next section, I’m going to talke about the various tables in the database, and how they related to each other.
The first table is the ship list. Ships are one of three kinds of ‘objects’, that link to many of the reports.
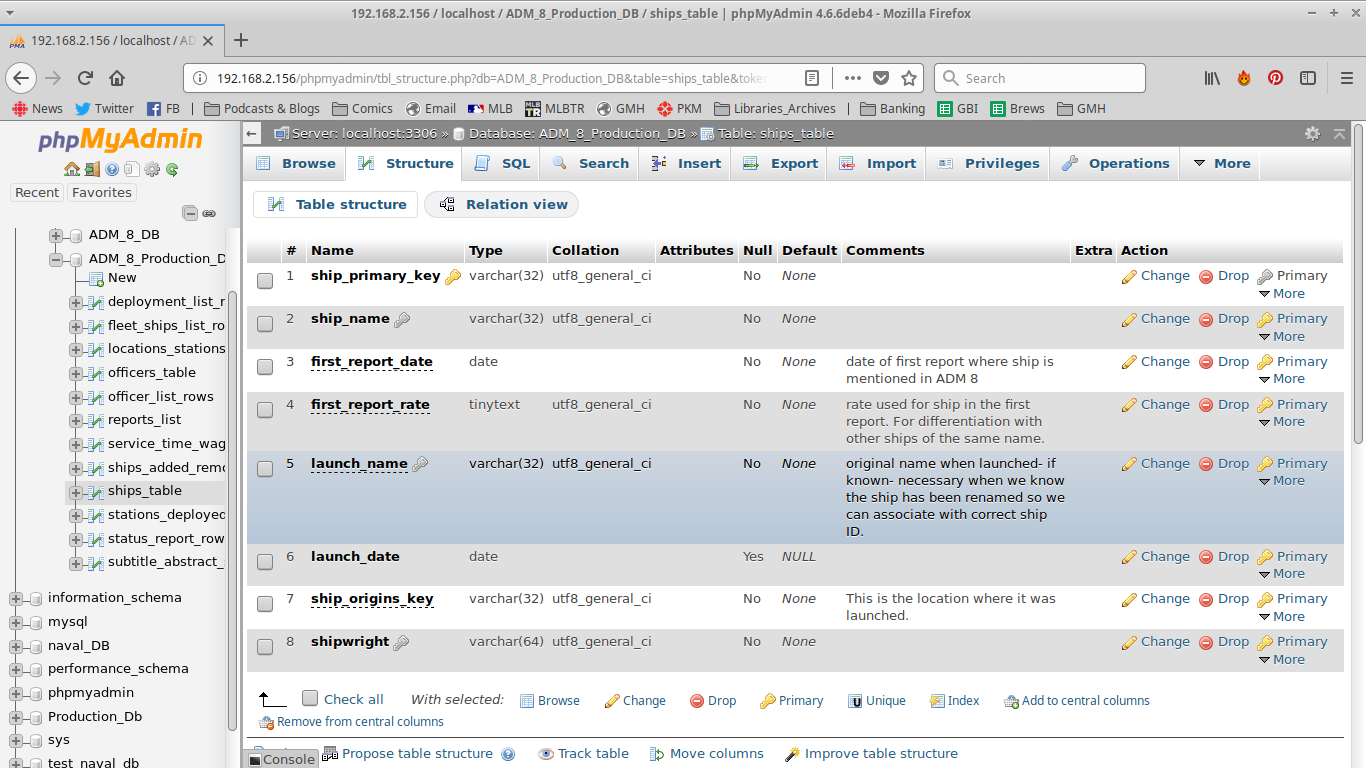
As you can see here, the structure of the ships table contains a whole bunch of data. Usually, the only data in a report is the ship name- but really, it’s a ship’s name as written. The difference will be discussed in the next blog. The other information in this table is to help differentiate the ships of the same name. Most of this information is actually available in ADM 8 records.
 The Officer table is the same thing, but for officers. The data – title, first adm8 reference date and first rank reference are determined by the first report in ADM 8 that they appear in- so again for internally differentiating various officers of the same name. In this case, “Note” are for things like “Father” and “Son”.
The Officer table is the same thing, but for officers. The data – title, first adm8 reference date and first rank reference are determined by the first report in ADM 8 that they appear in- so again for internally differentiating various officers of the same name. In this case, “Note” are for things like “Father” and “Son”.
 Locations are the third main kind of “object”. As you can see, this is much less complicated- the longitude and latitude data is not currently defined, but the plan is eventually to allow output to be displayed on a map/globe. It is important to note that Lat/Long will be decimal, rather than minutes and seconds.
Locations are the third main kind of “object”. As you can see, this is much less complicated- the longitude and latitude data is not currently defined, but the plan is eventually to allow output to be displayed on a map/globe. It is important to note that Lat/Long will be decimal, rather than minutes and seconds.
The fourth and final kind of main “object” are reports, as discussed in the previous blog.
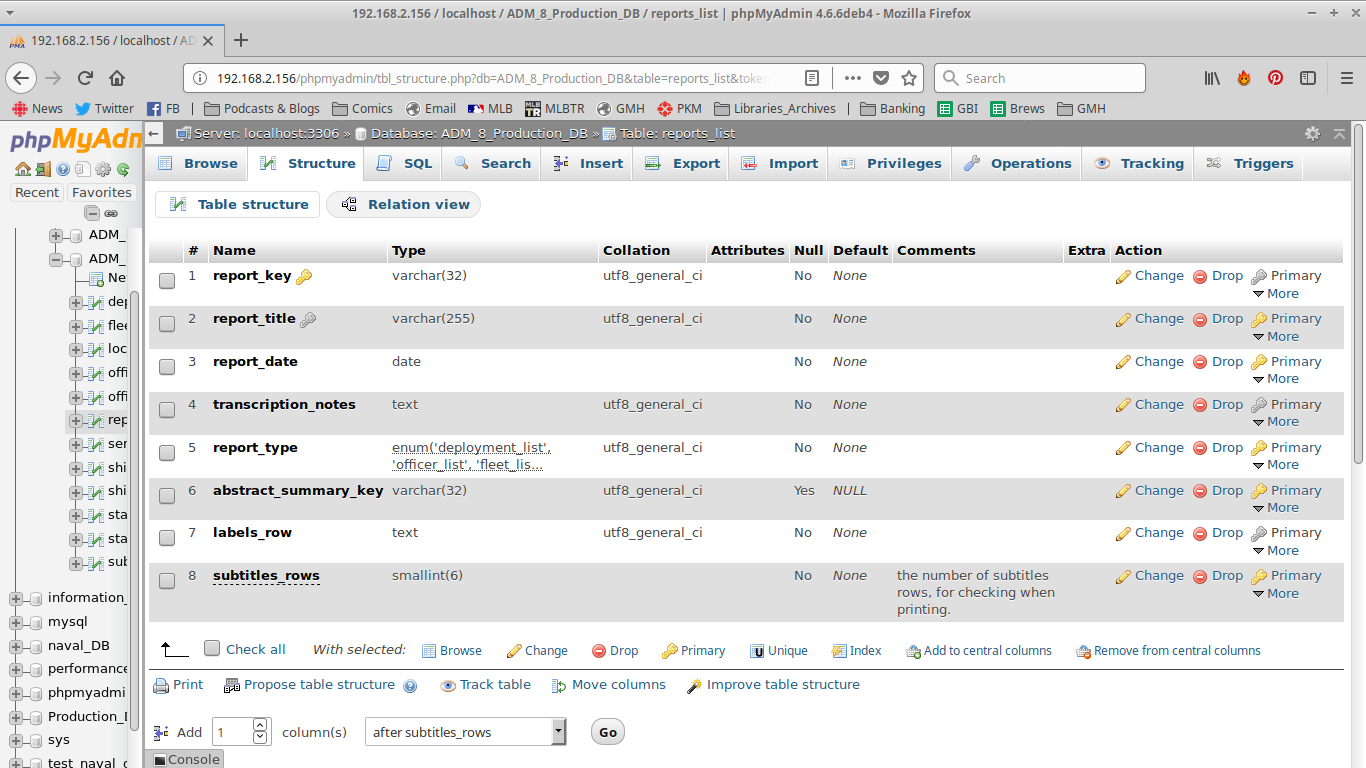
Each report that is uploaded is entered into this table. The one complex thing here is the abstract_summary_key field. This is a relic of an earlier design- at this point, if a report has an abstract or subtitle- its noted in the subtitles_rows column. The Labels row is the labels contained in the text of the report, which does not necessarily have a good relationship to the labels used in the transcription documents.
So when a report is uploaded, it is broken down into it’s component parts. Effectively, every line of every report gets its own line on a table. Each type of report has its own table, plus there are some tables that are shared by multiple types of reports.
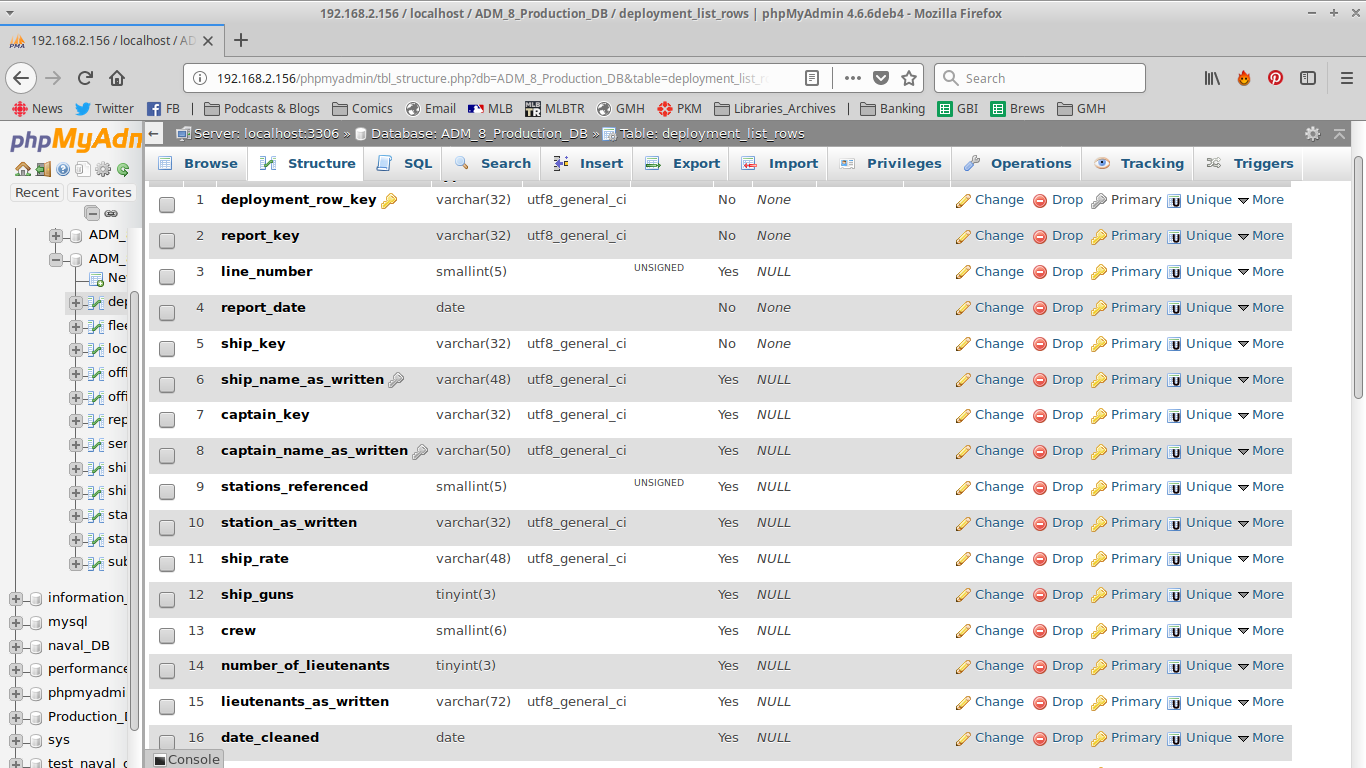 Deployment Rows is the table that (although badly named) contains the rows from standard disposition/deployment lists. As you can see, it repeats some of the data- like report date. This is so that when I am looking at pulling all the reports for a single ship, I only need to pull from this table. As you can see- there are quite a few different columns- and here you can really start to see name/name_as_written.
Deployment Rows is the table that (although badly named) contains the rows from standard disposition/deployment lists. As you can see, it repeats some of the data- like report date. This is so that when I am looking at pulling all the reports for a single ship, I only need to pull from this table. As you can see- there are quite a few different columns- and here you can really start to see name/name_as_written.
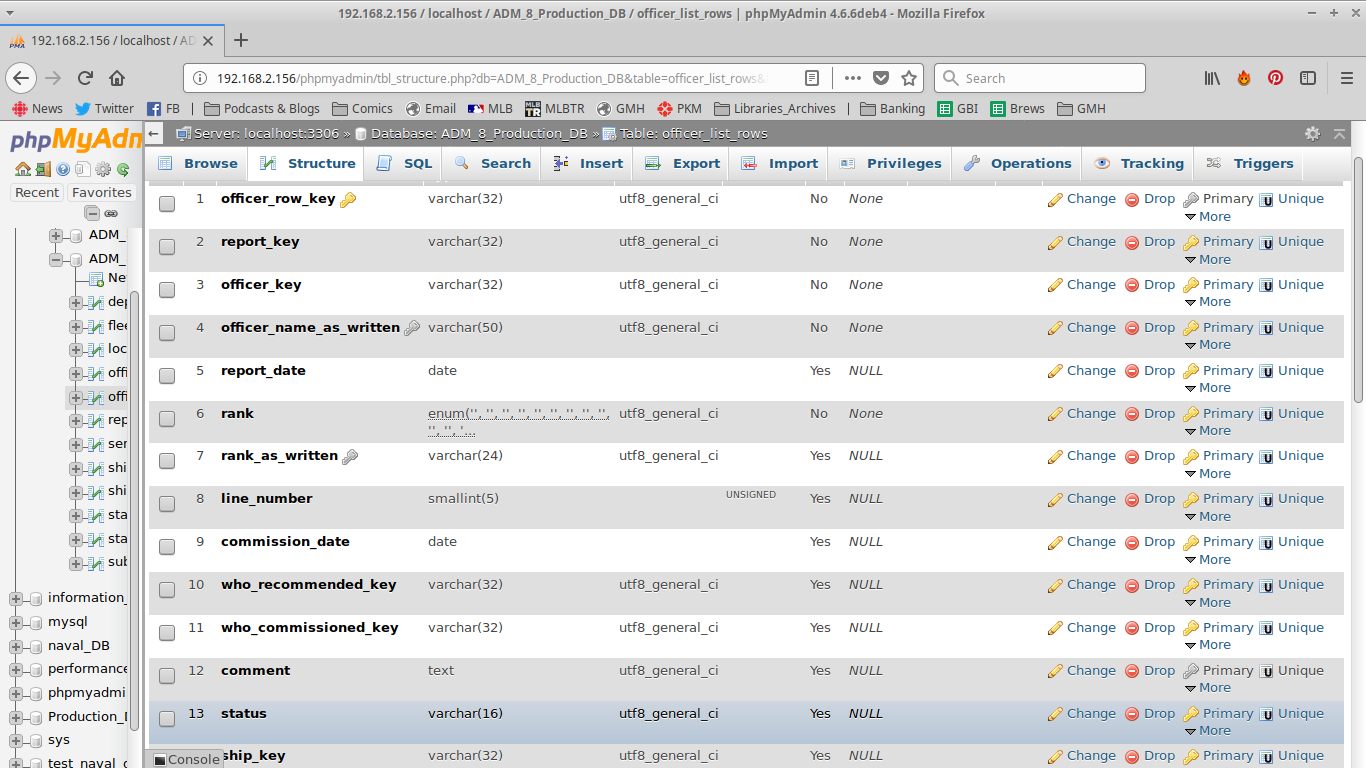 This is the table that contains the rows from officer lists- but, also, records of when officers are referenced in other types of reports. This so when I’m pulling all the reports pertaining to an officer, I just have to query this table to start.
This is the table that contains the rows from officer lists- but, also, records of when officers are referenced in other types of reports. This so when I’m pulling all the reports pertaining to an officer, I just have to query this table to start.
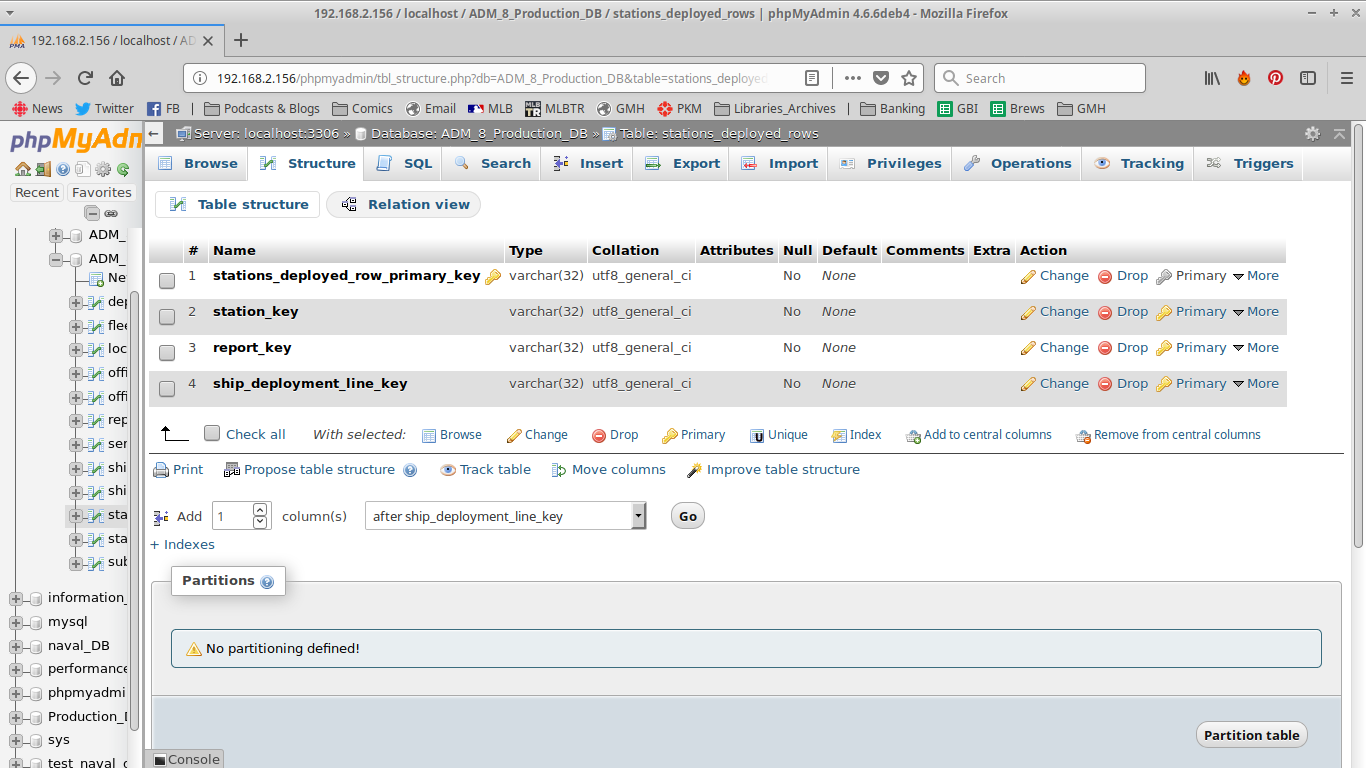 Locations are referenced in many different types of reports- and again, every time a location is referenced, there is an entry in this table. As you can see, the data stored here is actually quite limited. I kept it this way because some lines in reports refer to more than one location (for example, Scandaroone and Smyrna). Now in the previous types, you saw that the reports had name, name as written etc. What I’ve done here is kept that data in the report row. When getting all reports for a single location, it provides a list of report keys- and then a query is done for each report. This may be slightly slower, but considering MySQL is fast at doing reads, I’m okay with that.
Locations are referenced in many different types of reports- and again, every time a location is referenced, there is an entry in this table. As you can see, the data stored here is actually quite limited. I kept it this way because some lines in reports refer to more than one location (for example, Scandaroone and Smyrna). Now in the previous types, you saw that the reports had name, name as written etc. What I’ve done here is kept that data in the report row. When getting all reports for a single location, it provides a list of report keys- and then a query is done for each report. This may be slightly slower, but considering MySQL is fast at doing reads, I’m okay with that.
 This is the table for Service Time/Wages report rows. Some lines are actually missing- this is one of the more sizeable tables. The silver key next to the ship_name_as_written and location_name_as_written indicates that those columns are indexed, so they can be more quickly searched- if I get to the point where text searches are done through the interface.
This is the table for Service Time/Wages report rows. Some lines are actually missing- this is one of the more sizeable tables. The silver key next to the ship_name_as_written and location_name_as_written indicates that those columns are indexed, so they can be more quickly searched- if I get to the point where text searches are done through the interface.
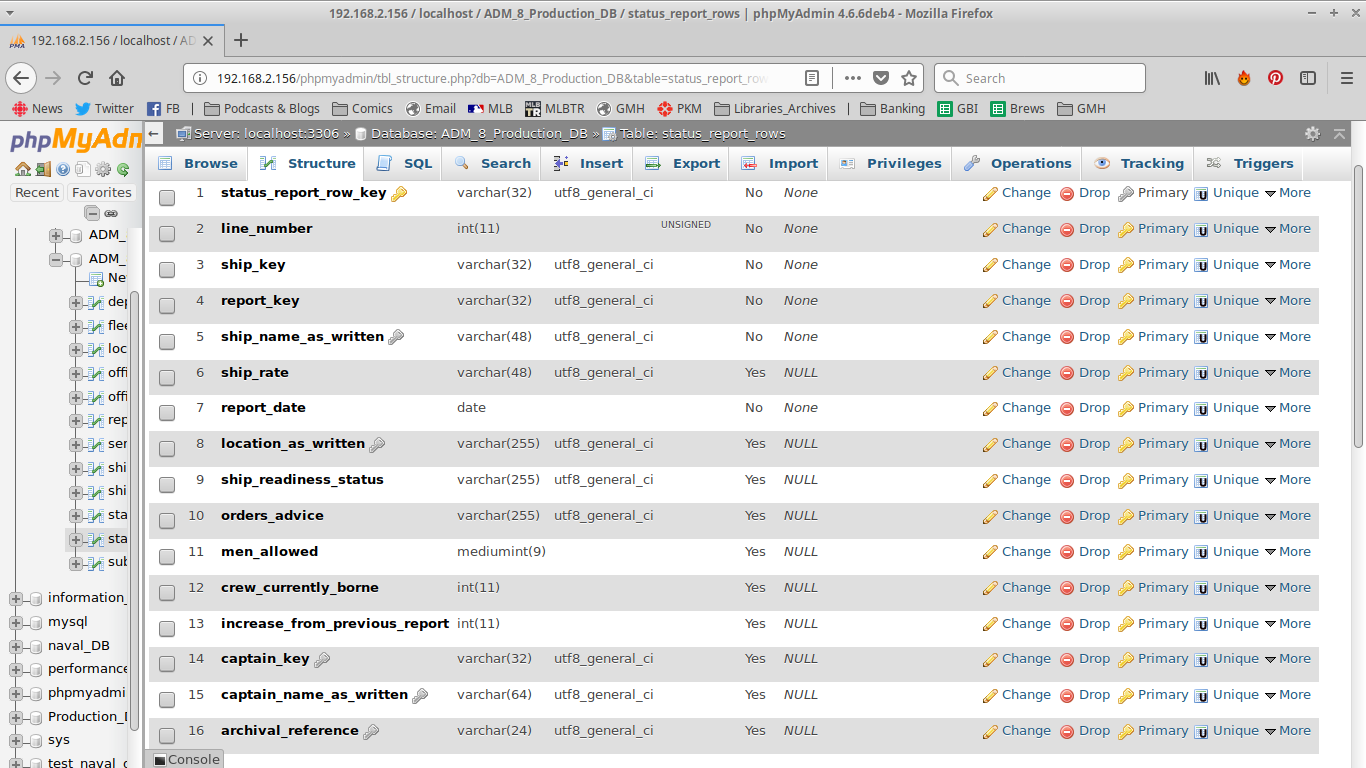 Status Reports are yet another type of report- and as you can see they have a very mixed set of data. There is a lot of overlap between these reports and the “disposition” lists. I decided to make them separate because of the crew complement columns, which are not in the majority of the reports.
Status Reports are yet another type of report- and as you can see they have a very mixed set of data. There is a lot of overlap between these reports and the “disposition” lists. I decided to make them separate because of the crew complement columns, which are not in the majority of the reports.
 The final type of table I’m going to talk about today are the Status/Abstract rows. Many reports have rows that have subtitles- or group ships together, like “6 Navy Yachts” or “12 Barges”. Those rows can’t be done properly in the other tables. Further, other reports have abstracts at the end that total the number of ships/men/wages owed. This table exists for those rows- which will also be talked about further in the next post.
The final type of table I’m going to talk about today are the Status/Abstract rows. Many reports have rows that have subtitles- or group ships together, like “6 Navy Yachts” or “12 Barges”. Those rows can’t be done properly in the other tables. Further, other reports have abstracts at the end that total the number of ships/men/wages owed. This table exists for those rows- which will also be talked about further in the next post.
Now, It’s true that I’ve not shown you all the tables that will exist- I’ve not transcribed any fleet reports, or ship addition/removal reports yet, for example so those tables don’t exist yet. However, as those happen I will modify and add those screen shots as well.
Database Structure and Data Types/Storage
Having shown you the tables, I want to talk a bit about data types and storage.
It is incredibly important to plan ahead and be consistent. For example, knowing that the MySQL “Date” data type can deal with dates from any year (I use 0001-01-1 to replace NULL) is incredibly handy. Also, make sure that all similar types of values- for example all of your keys- have the same data type and size (I use Varchar (32)). I’ve also run into problems with characters sets- particular with the apostrophe or single ” ‘ ” character being interpreted as latin-1 when I wanted UTF-8. As I’m only working with 4 or 5 reports at the moment, I can afford to restart the “production” database when I figure out I have a problem- but that won’t be true for very long. It’s also important to consider the capabilities of the various types- for example, there are problems with enumerated lists- like if the value don’t quite match. In general, if your database server has an already specified data type that will work for a field- use it, instead of something like varchar or text.
In the entry in this series (which will appear in January 2018), I will be discussing the process of transcribing documents, and also the PHP scripts which upload the documents into the database.




Not duplicating data in a database is quite important for data integrity. I suggest a quick read about database normalisation.
Also I recommend you change your primary index field on your tables to be an unsigned integer with the auto increment attribute, it’s much much quicker than a string field search.
Hi Cy,
thanks for your advice. I totally agree about duplication of data- and the current version of the database has *much* less duplication of data per “report-row” than earlier iterations. At this point, I believe that the only data that is duplicated for a single row is the report date- which gets put into the Reports Table, but also into the main table for each type of report data (eg, each row in the Ships Deployment table, the Officer List data, the Status Report Rows table etc). I *could* have just done it in the report table, and then used a JOIN to get that- in fact that’s probably what I should have done (since the DB is relational) but at the moment I’m not worried about it. As for the Primary Key, while I’m sure using an integer would be somewhat faster, since the size of the database (when I’m done transcribing ADM 8 v1 and 2) will only be in the range of ~400MB, I’m really not worried about that kind of time saving. When I get into larger projects- like if eventually I expand this project to cover more volumes, or when I do the HBC Ships’ Logs project, then I will absolutely look for any efficiency I can in the DB.
Hi Samuel
Ok, just trying to help you avoid some of the pitfalls I went through with Three Decks.
Thanks for the good work, I appreciate the efforts. As I’m part way though transcribing ADM 6 (all volumes) I understand the effort involved.
Hi Cy,
are you building your database with open data in mind? It’s something I need to start trying to work towards. With the next project, if not this one.
Sort of, it’s a relational database, with a much wider spread than yours, 120+ tables at the last count, but some data types are data controlled. The dimensions of a ship, for example, has a table listing all the possible fields and their type (volume, mass, length etc), the values are then stored in a table with the dimension id, cross referenced to a table of measurement types (feet, meters french Pied etc) which also contains conversion factors and various other things so it’s as flexible as possible. It means that the main table is really just a list of index ids and one alue column, the output data is generated from SQL statements with lots of joins.
If you want to go for an open data design have a look at EAV (Entity, Attribute, Value) structures, they allow a completely soft approach to data storage with no need to know what data fields you need before hand.
EAV basically consists of three levels of data, an Entity (ship, commander, port etc), an attribute, the data name, and a value. Basically you need a front end which allows you to add entities, attributes related to entities and then values for the attributes which are linked to an entity id (the specific ship etc.). Only slight complications are you might want multiple value tables for different data types, which means an attribute table needs to contain a data type as well an you may want the same attribute on multiple entities (E.g. name varchar(50) which means a pivot table to link them. It has the major advantage that you never store empty or unassigned values so reduces DB size significantly (I wish I’d started that way, I now have 600k rows and a db of nearly 200MiB in size).
We’re definitely doing things a little bit differently- while I have ship, officer, and location tables, these have *very* little to them other than “proper name”, key, and the first time they’re referenced in ADM 8. For me, the database is all about the rows of the reports, and that’s where all the data is. So for example, the dimensions of ships are in the Fleet List Rows table, and since there are 10 of those reports- each ship mentioned will have up to 10 different sets of dimensions (depending on the data) – and more, for some, since some ships actually have two rows in those reports.