

Welcome my friends to the show that never ends. We’re so glad you could attend, come inside, come inside.
In the previous two posts in this series, I discussed the documents that are part of ADM 8 volumes 1 and 2, and the database design. In this post, I will discuss the process of transcribing the documents. Since the beginning of this project, the general methodology hasn’t changed: I transcribe the documents into a comma separated values file (.csv), and then I use a PHP script to parse the file, and and do the database work. However, the specifics have changed quite a bit, especially recently as I managed to solve some nagging issues.
Transcribing the Documents
For purposes of clarity, I’m going to use examples of the same document all the way through this blog. As has been mentioned elsewhere, this isn’t the first project to put information from ADM 8 online, and others such as the Three Decks project have existed for a while. There is a substantial difference however- where projects like that seek to create a reference resource, and so extract the information from records like ADM 8, my project seeks to make ADM 8 itself (rather than merely the information it contains), much more accessible, and analyzable.
My approach to ADM 8 works because each of the documents within this report is composed of individual lines of data, where (most) lines within a report have all of the same columns and information- there are some where say, section A of the report is “Ships in Ordinary” and have different columns than section B “Ships Deployed” – however they are consistent enough that they can still working within the same transcription framework.

ADM 8/1 f20 verso & 21 recto. Photo credit to JD Davies

ADM 8/1 f112v and f113r. Photo Credit to J.D. Davies
These two examples are both from ADM 8 volume 1. Together they demonstrate much of what has to be dealt with/ included in a transcription. The first and most important goal is that the documents have to reproduced in the CSV in such a way that they can be then reproduced on screen in a way that is .. mostly faithful to the original documents. (Sometimes column orders change. I’ll talk about this in the next blog, about the user interface).
So, how does the transcription work? First, I create a template for each report type (the types of reports- with examples- are in part 1 of this series). Below is an example of the template for the “Wage/Service Time” reports.
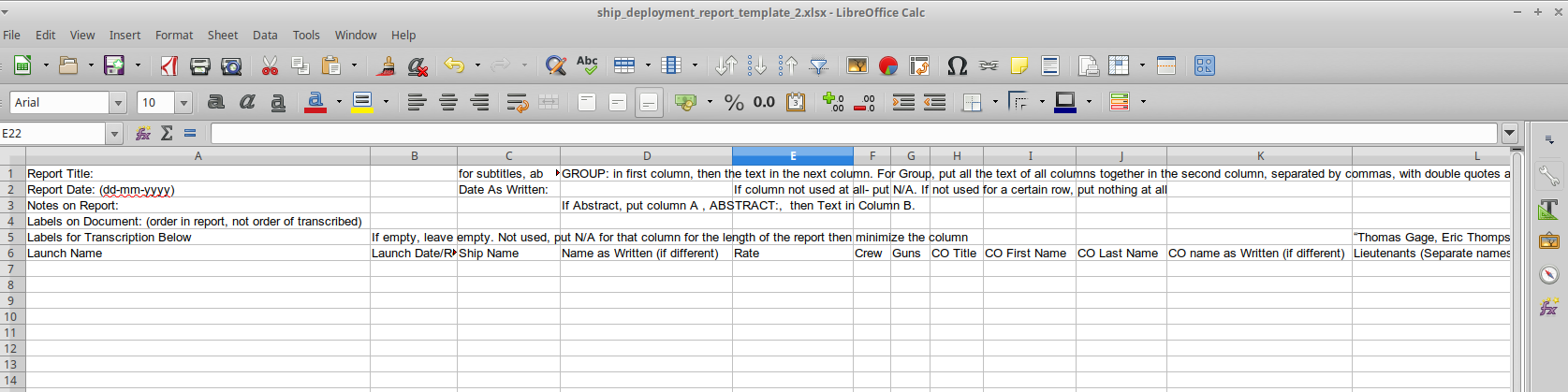
Creating consistency is necessary because I also create a single PHP upload script for every report type.
The transcription document is effectively divided into two sections. First, the “file headers”, or the general information about the report- which takes the first 4 or 5 lines of the file. This contains the Title as written, including special characters. One of the great things that I’ve recently done is that I’ve realized that special characters- such as ẞ can actually be stored/represented, which means that the text of the reports in the documents will be as faithful as possible to the text. The second, usually much longer section, are the report lines- each corresponding to a line in the report. Not every line is full of the same data- from the first example, you can see ‘summary’ lines following every section, and in the second example you see subtitles at the head of section. Later in the document from the first example there are lines that refer to groups of ships- for example “4 barges”, with 48 men. These cannot be dealt with in the same way. Likewise, in the Fleet List from 1 Jan 1678, the sections for 1st and 2nd both contain lines for “new ships” and in the Fleet List from 1679m, there are several lines for third rates where the builder and shipyard is noted, but the names left blank.
When the PHP script parses the file, it reads it in a line at a time.

ADM 8/1 f130 verso. Photo credit to JD Davies.
This screenshot shows what the transcription process looks like- I do my transcribing in LibreCalc (Excel for Microsoft folks) but they are really text files. Using a spreadsheet program for the transcription makes things so much easier for double checking and keeping the transcription organized (and CSV files are something they work with natively). The problem is, because CSV are text files and don’t contain formatting- you have to be *very* careful when you open up files, or when you’re transcribing to stop autoformatting- especially with dates/numbers. For example, The Fleet List from Jan 1679 uses feet and inches to describe the length, breadth, depth and draught of the ships in the list- but it doesn’t use single and double prime (‘ and “), but a period instead so 129.10 instead of 129’10”. When I opened the file the second time to continue transcribing, all of the numbers which noted 10 inches were autoformatted to floats (decimals).
The transcriptions contain *much* more information than the original document, and also, in some circumstances, misses things out.
What’s added is that I have multiple columns for information that relates to the date, to ships, locations, and officers. Specifically, there is a column for “true” values, and columns for “as written” values. These serve two different purposes- the former are for the upload script, and the latter are stored to be displayed for users to see. This is where the ability to include the special characters and things is important. This is where one of the key differences between my project and Three Decks- the difference between extracting the information and transcribing the documents as a whole. Also, researchers will be able to use this project to compare the information contained within similar documents (for example between the 10 fleet list reports from Jan 1678 to 1688). This also allows me to deal with rows like the examples mentioned above of the third rates from the Jan 1679 where the name is left blank- by using other records, I’ve been able to identify those ships. and put their name in the ‘proper name’ column while the ‘name as written’ column is left blank. It also, for example, allows me to record certain marked changes. For example. in the Jan 1678 Fleet List, the third rate Hope was originally written as Sandwich, but the latter is struck out. (This was noted by JD Davies in the middle movement of his trio of excellent blog posts about warship naming practices following the Restoration). This is noted in the transcription as “Hope (Sandwich struck out)”. I’ve also added “other people mentioned” and “other locations mentioned” to each report type- because notes can often contain things like “bought from C. Young” or “cast away off Tangier”, which aren’t in the “normal” columns for that report, but I still want to be able to make sure that those lines are properly associated with those officers or locations (and so would be displayed if a researcher choose that officer or location to look at).
What’s missing, unfortunately, is quite a bit of the – extraneous marks on the page, that can’t really be accommodated in a CSV file. For example, there are non-zero number of reports where a group of ships will be included in a curly bracket with a single notation for their station/duties/location. I haven’t thought of a way to accurately record that. It could be done, visually, if users only viewed whole reports- but a major part of this project is the ability to pull all the individual rows associated with a single ship, officer, or location, so sticking a symbol/character randomly in a line (although it could be omitted when pulling single lines) just isn’t worth it- especially when it would be very fiddly to get right. It could probably be done if I was somehow using LaTeX to display reports, but all I’m doing is HTML & PHP for this first version of the project. There is a space in the ‘header’ rows for notes about the report as a whole- which can for example describe features like the use of non-English characters or marginalia. There is also a column on each line for a note- which can contain the information which doesn’t fit in the other columns.
Now, for storage/copyright reason, the ADM 8 project will not contain/display the images of the documents directly- but specific references are included for each row of each report so that researchers can return to the original documents for comparison (as they should). I should also note- I do not argue that the information contained in ADM 8 is necessarily accurate- the goal is to make ADM 8 more accessible, not necessarily to provide a |true record| of where the Royal Navy’s ships were at any point (or how much money was owed, etc).
Due to the length of this post, I will discuss the upload scripts in my next post.






Excel can be problematic for dealing with CSV files. First of all it still doesn’t default to using UTF-8 for text encoding but windows-1252 (or whatever your locale settings give as the default encoding) and it’s almost impossible to persuade it to use UTF-8, so your characters like ß will tend to get mangled. Next it tends to think it knows best about formatting so if you choose to use leading zeros on dates for example it will remove them, and I’ve had a chap called Mr True have his surname changed to TRUE as Excel decided it was a Boolean. Date handling is a complete mess in Excel, though fortunately for your period it doesn’t recognise anything before 1900 as a date, but geneticists have found that it will turn gene symbols into dates so eg 3MAR gets turned into 3/3/2018 (or whatever the year is when you open the CSV file in Excel.
Hi David,
you’re absolutely right.
I actually use LibreOffice instead of Excel, and every time I open a .csv file a dialogue comes up which confirms that It should be opened in UTF-8, and also allows me to format each of the columns before opening the document- and I always open them all as text so that LibreOffice doesn’t start mucking with the data. It actually can deal with dates prior to 1900- but I am now always inputting dates as yyyy-mm-dd b.c that way I don’t have to muck with them at all when they go through the PHP into the database (which does the same format). I very much prefer working in LibreCalc to TExtEditor b/c I can visually organize it, where as I get very confused when it’s just a mass of ,,,,,,
Sorry, I realised you were using LibreOffice, but you mention “Excel for Microsoft folks” so I thought I’d just put a health warning up. Of course you can use LibreOffice on Windows too, but depending on situation you may have to convince an IT Helpdesk to install that in addition to MS Office.
Thats totally fair. I would suggest that people use LibreOffice anyways.